
Cloudflare experienced a significant outage affecting its R2 object storage service and several dependent services. The outage, lasting 1 hour and 7 minutes, resulted from a human error during a password rotation process. This incident highlights the critical need for robust operational procedures and automated safeguards in large-scale cloud infrastructure.
The Root Cause: A Simple, Costly Mistake
The outage, which occurred between 21:38 UTC and 22:45 UTC, was directly caused by a misconfiguration during the rotation of credentials for the R2 Gateway (the API frontend to the R2 object storage).
New credentials were mistakenly deployed to a development environment instead of the production environment. When the old credentials were subsequently deleted, the production R2 Gateway was left without valid authentication, causing widespread service disruption.
The root cause was the omission of a single command-line flag, --env production, which is essential for directing the deployment of new credentials to the correct production environment. This seemingly minor oversight resulted in a complete loss of access to the backend storage for the R2 Gateway.
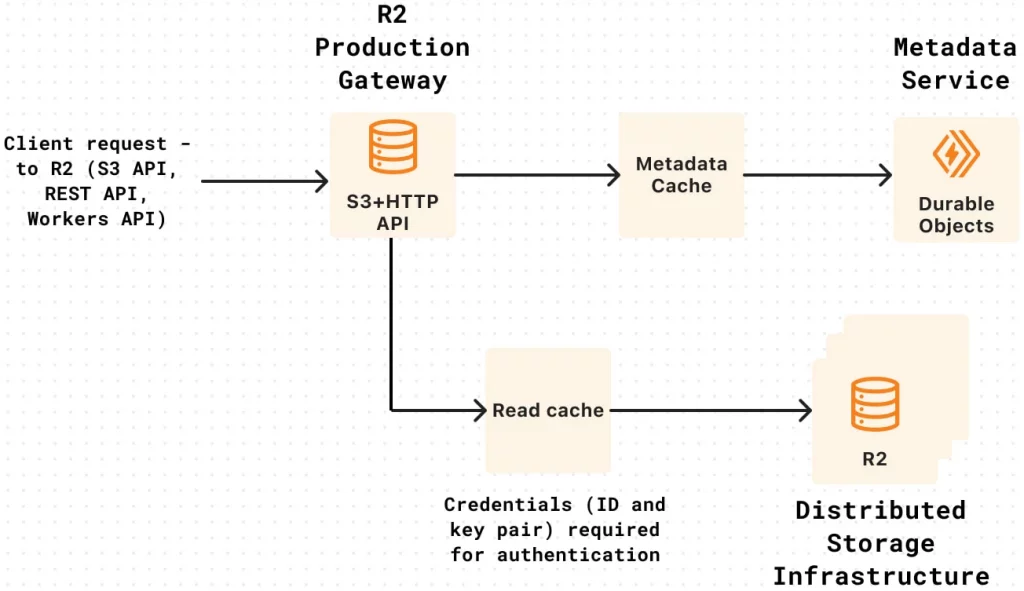
R2 Gateway Worker authentication diagram
Source: Cloudflare
Cloudflare’s incident report explains the delayed discovery: “The decline in R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure,”
They further stated, “This accounted for a delay in our initial discovery of the problem. Instead of relying on availability metrics after updating the old set of credentials, we should have explicitly validated which token was being used by the R2 Gateway service to authenticate with R2’s storage infrastructure.”
Impact of the Outage
The outage resulted in significant service degradation across multiple Cloudflare services:
- R2 Object Storage: 100% write failures and 35% read failures (cached objects remained accessible).
- Cache Reserve: Increased origin traffic due to failed R2 reads.
- Images and Stream: All uploads failed; image delivery dropped to 25%, and Stream delivery to 94%.
- Email Security, Vectorize, Log Delivery, Billing, Key Transparency Auditor: Various levels of service degradation.
While Cloudflare confirmed that no customer data was lost or corrupted, the outage caused substantial disruption for users relying on these services.
Cloudflare’s Response and Preventative Measures
In response to the outage, Cloudflare has implemented several changes to prevent similar incidents:
- Improved Credential Logging and Verification: Enhanced logging and verification processes to provide better monitoring and detection of credential issues.
- Mandatory Automated Deployment: The use of automated deployment tooling is now mandatory to reduce reliance on manual processes and minimize human error.
- Updated Standard Operating Procedures (SOPs): SOPs are being updated to require dual validation for high-impact actions like credential rotation.
- Enhanced Health Checks: Improved health checks will enable faster detection of root causes in future incidents.
This incident follows a similar outage in February 2025, also caused by human error. In that case, an operator mistakenly disabled the entire R2 Gateway service while responding to a phishing report. These repeated incidents emphasize the need for more robust safeguards and checks.
Lessons Learned
This incident serves as a stark reminder of the potential consequences of human error in complex systems. Even seemingly minor mistakes can have significant and widespread repercussions. The importance of robust operational procedures, automated safeguards, and rigorous testing cannot be overstated, especially in critical cloud infrastructure. The lack of immediate detection mechanisms and reliance on indirect metrics also played a role in the extended duration of the outage.







